Benchmarking the AWS Graviton2 with KeyDB – M6g up to 65% faster
We’ve always been excited about Arm so when Amazon offered us early access to their new Arm based instances we jumped at the chance to see what they could do. We are of course referring to the Amazon EC2 M6g instances powered by AWS Graviton2 processors. The performance claims made and the hype surrounding the Graviton2 had us itching to see how our high-performance database would perform.
This article compares KeyDB running on several different M5 & M6g EC2 instances to get some insight into cost, performance, and use case benefits. The numbers were quite exciting with the AWS Graviton2 living up to the hype, we hope you enjoy!
KeyDB is a multithreaded superset of Redis that has been able to get up to 5X performance gains vs. Redis (node vs node) due to its advanced architecture. We have done a lot of benchmarking on AWS instances (compare here) that shows clear advantages using certain instance types over others. To date, M5 instances have been the fastest general-purpose Amazon EC2 instances available on AWS so comparing a potentially faster M6g was an interesting lineup.
Performance & Cost#
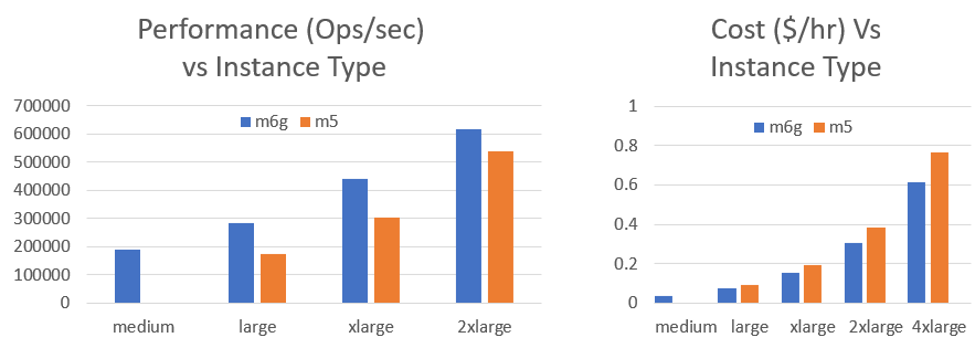
This first chart compares the performance of several different instance sizes looking at the ops/sec throughput that each instance can achieve. The second chart contains the associated pricing of each instance type. You can compare M6g pricing by selecting US East (N.Virgina) here
M6g Takes the Lead#
The M5 instances use Intel Xeon Platinum 8175 processors which typically get us really good results over most other instance types available. It was shocking to us that on the smaller M6g instances, using AWS Graviton2 processors, there was such a huge gain over existing M5 instances for KeyDB.
The m6g.large is 1.65X faster than the m5.large and the m6g.xlarge gets a 1.45X gain over the m5.xlarge. As the number of cores increase the gap starts to narrow between the offerings. However, we are still investigating the performance of the m6g.2xlarge and m6g.4xlarge as we believe we can get the performance levels up to the same multiples. We did not do any tuning specific to the M6g in this test so we’re optimistic about results to come.
It was also nice to see there is an m6g.medium instance (not offered with M5) as part of the M6g offering which enables another powerful lower cost option. What is apparent from the charts above is that not only do the M6g instances provide major performance gains over the M5, it is also 20% cheaper!
What this Means to Users#
KeyDB is a really fast in memory database. As such, our users value memory and performance. KeyDB has been an advocator for our ARM users and use cases. We are happy to be able to support the M6g which is showing to be a strong contender to its x86 counterpart. For those keeping all data in memory, a lower memory cost and additional computing power make a compelling case for the M6g.
For users trying to reduce costs, scaling database size proportionally with computing resources can be a tough balance. There are a lot of users that become memory bound first when selecting EC2 instances. When optimizing resources and reducing costs, the KeyDB FLASH feature is often selected, which enables a fast FLASH tier in addition to RAM. The M6g line complements these cases with powerful smaller instances which enable some of the most affordable and resource optimized database solutions available.
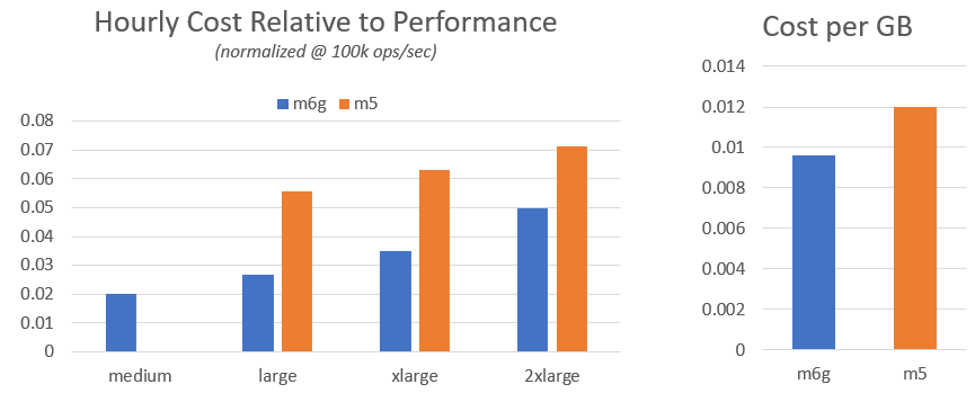
The first chart below demonstrates the cost relative to performance. This chart represents “bang for your buck” where the m6g.medium provides the most computing for your dollar and each successive size also provides major savings regarding computing power. The second chart looks at memory (RAM) where on a GB to GB scale, the M6g instances also provide more memory per dollar spent.
In both cases below, the lower values are better, providing a lower cost per resource
Conclusions#
Looking at the results above the M6g instances are 20% cheaper on a per GB scale. This can provide cost savings across the board to users, especially those selecting machine size based off available memory.
When it comes to the cost of work, some M6g instances can be over 2X cheaper when looking at computing cost / performance. The m6g.medium provides the best bang for your buck with the m6g.large and m6g.xlarge also with major benefits.
Looking at straight up performance, the m6g.large is 1.65X faster than m5.large and 1.45X faster comparing the ‘xlarge’ instances.
It is clear that not only can these processors provide a performance boost, but also significant cost savings! It seems AWS Graviton2 has lived up to its claims when put to the test. With competitive pricing it looks like Graviton2 will be making its mark in the cloud business.
Find out More#
- AWS Pricing (select N. Virginia region)
- Technical details on the AWS Graviton2
- KeyDB Website
- KeyDB Open Source Project on Github
Reproducing Benchmarks#
We encourage users to try out the M6g to see what kind of improvements and/or savings can be seen relevant to your use case. This section reviews benchmarking steps to reproduce the results shown in this blog. We also look at a few tips to help mitigate bottlenecks and testing variance. Avoid Bottlenecks:
- We use Memtier by RedisLabs for benchmarking. Because of KeyDB’s multithreading and performance gains, we typically need a much larger benchmark machine than the one KeyDB is running on. We have found that a 32 core m5.8xlarge is needed to produce enough throughput with memtier. This supports throughput for up to a 16 core KeyDB instance (medium to 4xlarge)
- When using Memtier run 32 threads.
- Run tests over the same network. If comparing instances, make sure your instances are in the same area zone (AZ).
- Run with private IP addresses. If you are using AWS public IPs there can be more variance associated
- Beware running through a proxy or VPC. When using such methods, firewalls, and additional layers it can be difficult to know for sure what might be the bottleneck. Best to benchmark in a simple environment and add the layers afterwards to make sure you are optimized.
- Keep in mind latency numbers are relevant to eachother. Memtier tests push maximum throughput. Tools such as YCSB are great for dialing in on latency numbers under different loads, not just max throughput.
- When comparing different machine instances ensure they are in the same AZ and tested as closely as possible in time. Network throughput throughout the day does change so performing tests close to eachother provides the most representative relative comparison.
- KeyDB is multithreaded. Ensure you specify multiple threads when running
Set up KeyDB#
You can get KeyDB via github, docker, PPA (deb packages) or RPM. Once you have it installed, start it up with the following configuration parameters passed to it:
Try running on different instance types as shown in this blog
Set up Memtier & Benchmark#
Install memtier from github. Once installed you can run tests with the following command line:
Both memtier and KeyDB assume port 6379 but it can be specified. You need to set up your aws security group rules to allow access through this port. The above command will return all misses if running on an empty database. In order to load up the database you can with this command:
This will return representative numbers when running a normal benchmark. If you would like to get 100% hits on a benchmark you will have to load it with all writes first via the following command:
When you run a normal benchmark it will now return 100% hits
Concluding Remarks#
The ratios seen in benchmarking remained approximately the same regardless of the hit/miss/read-write setup. Numbers displayed are averaged. This is looking at a relative comparison between the M5 and M6g. Run a few consecutive tests to ensure repeatability. If there is variance it can help to increase --requests=20000 or higher (default is 10000).