Single KeyDB Node Achieves Thoughput of a 7 Node Redis Cluster
KeyDB is a high performance fork of Redis that’s able to hit 1,000,000 ops/sec on a single node, without sharding. This article not only discusses the performance, but the benefits that go along with it. More power means less moving parts to do the same job, and the semantics of that statement are worth discussing.
KeyDB is fully compatible with Redis protocol, modules, and API and will work with Redis clients. KeyDB is an open source project focusing on simplicity and adding features that may never be incorporated into Redis.
The Chart below demonstrates that even on a single machine (instance) a cluster may be required to get maximum throughput. Any more than 7 shards on a single machine stops showing improvement.
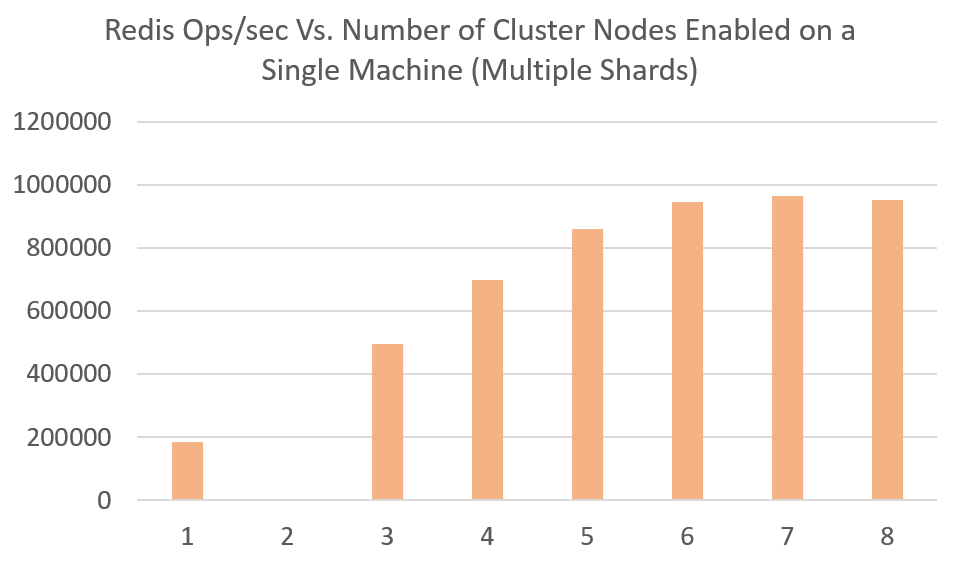
Running a cluster on a single machine enables improvement but eventually hits limits of what can be processed. Obviously scaling and sharding to different machines will scale linearly without diminishing returns.
KeyDB regardless of how you shard can get the max throughput on a single machine through multithreading. In reference to the above chart, KeyDB would maintain close to 1 million ops/sec in any of the configurations above (enabling more or less threads per shard).
If a cluster is being run on a single machine to get higher throughput, a single multithreaded node can simplify. This can drastically reduce the amount of sharding when scaling and offers a many benefits we will discuss later in this article.
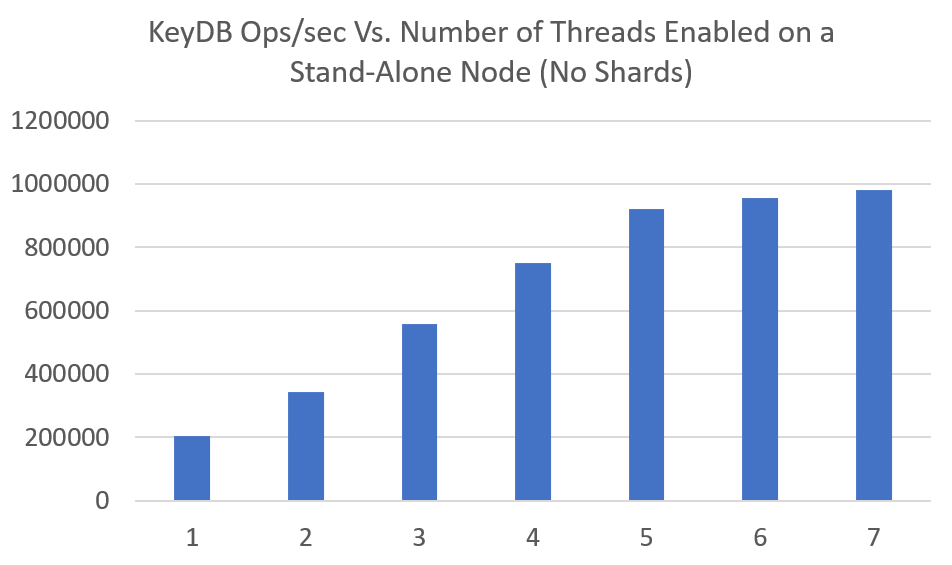
The chart below demonstrates KeyDB multithreading on a single node as more threads are allocated to it. Over 7 threads typically does not see further improvement on machines we have tested on. We have been able to benchmark a single node to 1.5million ops/sec, however this was in an isolated environment with powerful machines. The numbers below are easily reproducible on EC2 instances.
If you are not yet running a cluster…#
Its simple, you can increase your performance enabling higher throughput/volume. There are a lot of devs/startups/smaller businesses out there who are not set up to shard, were not planning to shard, or maybe their use case requires features inhibited by clustering.
To be clear, we are not bashing the idea of sharding nor discouraging users from planning to scale. Obviously if you anticipate sustained growth that will surpass such a boost, you should start planning for it early.
For the cases where users are currently limited by a single Redis node, they can greatly benefit from multithreaded KeyDB as an easy swap out to their existing Redis server. This can provide up to a 5X increase to existing setups.
Users not yet clustering may already be dispositioned to limits of clustering or will need to consider them when planning to scale. There are several known limitations you must consider and plan for if you want to enable clustering. The list below outlines some of these cases. If its too much rework to resolve the issues, a multithreaded node can provide extra horsepower.
A few of the hard limits of clustering:#
- Not all clients support clustering. There are about 150 clients that currently have support for Redis (https://redis.io/clients) yet there are surprisingly a lot that do not have built in cluster support. Query routing and proxy assisted partitioning can assist for some of these cases but can add additional latency and complexity to the setup.
- There is not support for multiple databases. Each shard assumes DB0. If you are referencing another you will get an error.
- Operations involving multiple keys may not be supported. Ie. intersection of two sets where keys live on different nodes
- Transactions involving multiple keys routed to different nodes can not be used.
- A data set with very large pieces may be limited. Ie. a huge singular sorted set or list cannot be sharded
For those sharding there are benefits using larger multithreaded instances:#
- The complexities of key balancing, and scaling with production spikes is greatly reduced
- Shard to each server instance once instead of multiple times. You can run one KeyDB node on a server to gain the benefits of running a 7 node single threaded cluster.
- Balancing hot keys can be easier. Larger node sizes and increased perf reduce the magnitude of the impacts. Not sharding as frequently reduces the chances of running into these issues.
- Huge keys (sorted sets and lists) are relatively smaller on larger nodes
- There are a lot less RDB files, AOF files, and moving pieces to manage. Manpower and system maintenance can be reduced. There are less parts to fail.
- The ability to accept more threads is another form of scaling. If you are presharding this reduces the amount of nodes to transfer.
Check us out#
If you would like to check out the open source project, KeyDB is on Github.
Keep up to date#
KeyDB has some cutting edge plans in store and we will be discussing some of these features in the coming months. To keep up to date with where the KeyDB project is going please subscribe to our mailing list. We feel strongly against spamming and try to keep our emails informative about the project.
Notes about benchmarking…#
Benchmarking was performed using Memtier by RedisLabs. The benchmarking instance was an m5.8xlarge instance and all 32 cores had to be allocated to produce sufficient traffic volumes for testing.
When benchmarking single nodes the default settings can be used with --threads=32. If benchmarking a cluster, the number of clients becomes way too high as each client writes to each shard. So less clients and threads need to be assigned to memtier appropriately to keep it from crashing (producing errors). This means in order to produce enough volume you must run multiple memtier instances simultaneously. We found it adequate running 3 memtier instances simultaneously, each with --threads=12, and adjusting the number of clients depending on cluster size to max out each instance.
KeyDB and Redis were tested on an m5.4xlarge. Clusters were set up manually, see example to set up a cluster here . KeyDB testing was configured with the following options set: --server-thread-affinity true and --server-threads “x” where “x” is number of threads for the given test.