A Multithreaded Fork of Redis That’s 5X Faster Than Redis
What if I told you there is a fork of Redis that can run 5x faster with nearly 5x lower latency. What if you no longer needed sentinel nodes and your replicas could accept both reads and writes? This could provide the potential to achieve a 10x reduction in the amount you shard.
This article looks at KeyDB which is an open source, multithreaded fork of Redis. We will review the latest benchmarking numbers and discuss how a more powerful, single instance of KeyDB can reduce cluster size and simplify your stack. We discuss the multithreading architecture and walkthrough how to replicate these numbers.
Why KeyDB? Why Consider A Fork?#
With an uninhibited ability to evolve the codebase, KeyDB has been able to make huge strides in a short amount of time and are on a path that will disrupt the database landscape in the months to come.
In regards to why fork Redis in the first place, KeyDB has a different philosophy on how the codebase should evolve. We feel that ease of use, high performance, and a "batteries included" approach is the best way to create a good user experience. While we have great respect for the Redis maintainers it is our opinion that the Redis approach focuses too much on simplicity of the code base at the expense of complexity for the user. This results in the need for external components and workarounds to solve common problems.
Because of this difference of opinion features which are right for KeyDB may not be appropriate for Redis. A fork allows us to explore this new development path and implement features which may never be a part of Redis. KeyDB keeps in sync with upstream Redis changes, and where applicable we upstream bug fixes and changes. It is our hope that the two projects can continue to grow and learn from each other.
Latest Benchmarking Data#
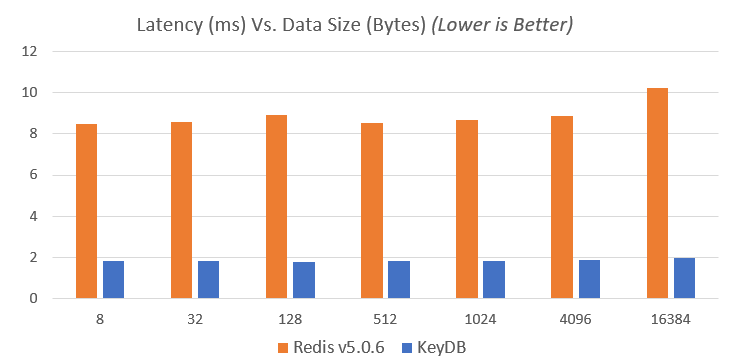
KeyDB launched in March of this year and even with our performance gains, we still expect to get even faster. Our latest benchmarking data shows a single instance of KeyDB getting just over 5 times more ops/sec (graph ranging 5.13-5.49) than a single instance of Redis (v5) and nearly 5 times lower latency (graph ranging 4.6-5.1):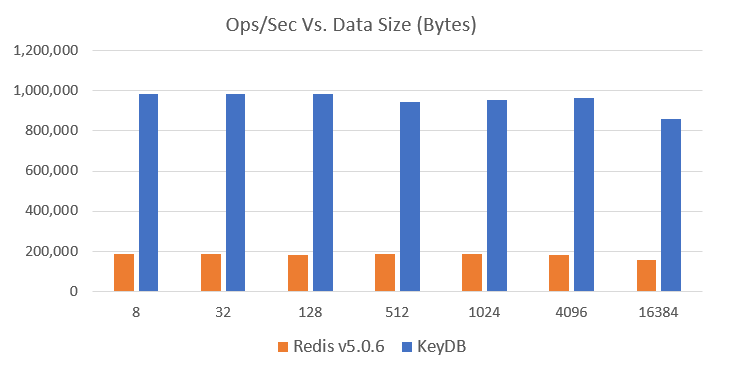
Benefits of Multithreading#
Being able to increase the power of a single instance/node of KeyDB reduces the need to shard and can greatly reduce the number of moving parts in your setup. You might be asking if running many Redis nodes in a cluster might get more throughput per core than multi-threading a single node? You can shard KeyDB just as you can Redis, and as your database grows extensively it makes sense to do so. But if you have the option to add horsepower without purchasing a second car why wouldn’t you? Being able to scale the size of your nodes in addition to sharding adds a new level of power and choice for the user. This is one of many differences of opinion between Redis and KeyDB. This is not only a common discussion point in the community but a point of contention in some circles.
So to the question of “what does it look like running more threads with KeyDB”. We ran some basic numbers so you can get an idea. Below is a chart benchmarking ops/sec vs number of threads used:
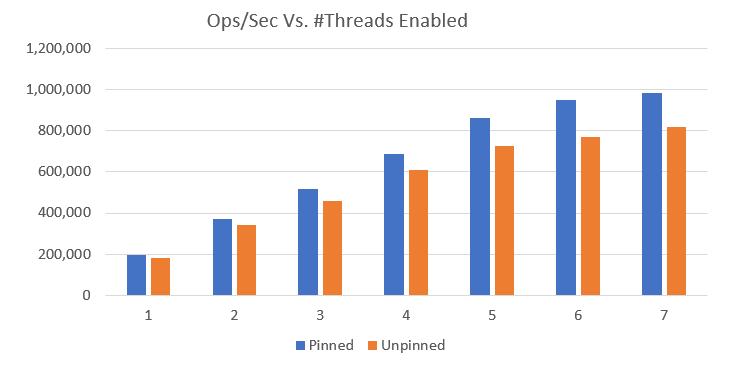
You can see drastic improvements to the performance as more resources are allocated to the instance. There is an option to pin threads to CPUs for further improvement but the best option for you may depend on your setup. By default this option is disabled.
At just one thread allocated to KeyDB, on average it still holds about 5% performance gain over a single threaded instance of Redis. So even with new features being added and architecture changes, performance has not been compromised.
Multithreading Architecture#
KeyDB works by running the normal Redis event loop on multiple threads. Network IO, and query parsing are done concurrently. Each connection is assigned a thread on accept(). Access to the core hash table is guarded by spinlock. Because the hashtable access is extremely fast this lock has low contention. Transactions hold the lock for the duration of the EXEC command. Modules work in concert with the GIL which is only acquired when all server threads are paused. This maintains the atomicity guarantees modules expect.
Unlike most databases the core data structure is the fastest part of the system. Most of the query time comes from parsing the REPL protocol and copying data to/from the network.
Future work includes allowing rebalancing of connections to different threads after the connection, and allowing multiple readers access to the hashtable concurrently
Optimizing Your Setup Further#
KeyDB believes in features that help simplify the user experience. Our Active Replica feature has been widely adopted and used in production with our latest stable version 5. This feature enables you to have two master nodes replicated to each other both accepting reads and writes. Best of all there are no sentinel nodes controlling the failover. You get high availability and maximize the use of your resources. If you are not already balancing reads to replica nodes, you could double your throughput with this option. This means moving from a simple master-replica setup of Redis to a multi-threaded active-replica setup with KeyDB could reduce your sharding requirement by as much as 10x. Take a look at this article ”Redis Replication and KeyDB Active Replication: Optimizing System Resources” for a deeper dive on the topic of active replication.
Check Out KeyDB#
To check out the KeyDB open source project on Github click here
Benchmarking – How To Reproduce These Tests Yourself:#
The most important thing when benchmarking is to ensure that your benchmarking tool is not the bottleneck. We needed to use an amazon m5.8xlarge instance with 32 cores assigned in order to produce enough volume for our single instance testing. Any lower and the benchmarking tool would be the bottleneck for these tests. For the testing instance we used Memtier by RedisLabs. The machine used for running the Redis and KeyDB instances during our tests was an amazon m5.4xlarge.
For the first charts comparing Redis and KeyDB, the following commands were used:Memtier: memtier_benchmark -s [ip of test instance] -p 6379 –hide-histogram --authenticate [yourpassword] --threads 32 –data-size [size of test ranging 8-16384]
KeyDB: keydb-server --port 6379 --requirepass [yourpassword] --server-threads 7 --server-thread-affinity true
Redis: redis-server --port 6379 --requirepass [yourpassword]
Memtier: memtier_benchmark -s [ip of test instance] -p 6379 --hide-histogram --authenticate [yourpassword] --threads 32 --data-size 32
KeyDB pinned: keydb-server --port 6379 --requirepass [yourpassword] --server-threads [#threads used for test] --server-thread-affinity true
KeyDB unpinned: keydb-server --port 6379 --requirepass [yourpassword] --server-threads [#threads used for test]