Redis Replication and KeyDB Active Replication: Optimizing System Resources
A lot of sites run replica nodes for high availability of their servers. Makes sense, but is this replica being fully utilized? Or are you just paying for high availability without getting the performance boost of essentially doubling your resources? This article discusses options used with Redis, as well as the active-replication option used in the Redis compatible database KeyDB.
KeyDB can be used as a drop in replacement database for Redis as it is fully compatible with Redis modules, API’s, protocols. KeyDB has everything open source Redis provides, but has many other powerfull and free options in its open source basecode such as flash support, active-replication, full multi-threading, aws s3 backup, etc. you can find out more here
KeyDB has introduced active-replication into its stable version 5.0 which essentially allows two master nodes with synchronous read/write and failover support. This allows load balancing of reads AND writes to both master nodes. Master nodes are made replicas of eachother, syncing with eachother while both acting as masters.
Setup of High Availability with Redis#
If you are running Redis in a simple high availability setup your setup likely looks something like this:
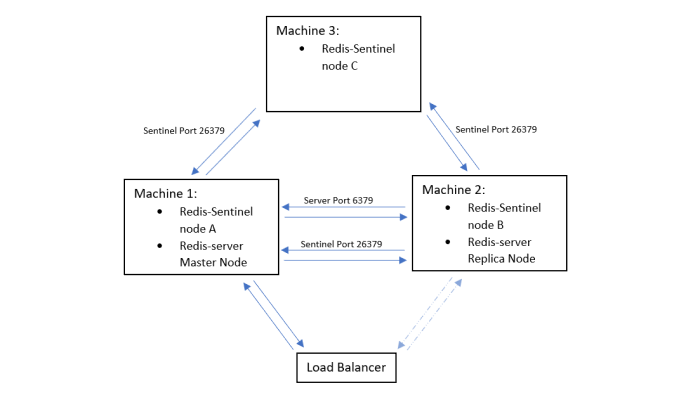
Setup of High Availability with KeyDB#
The open-source KeyDB has the option to use active-replication within the base code. This server can be swapped out with your redis-server easily to try out. If you are doing a high availability setup with KeyDB your equivalent setup would look like this:
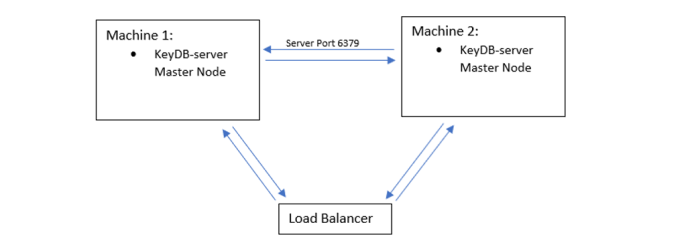
This set up has two identical master nodes replicated to eachother (active-replica enabled). You can now load balance between the two. Upon failure you only read/write from the active master. Split brain scenario is covered by timestamping. There in no reconfiguration of your nodes, and when your failed node/connection is restored, it will sync and function as it did before. This is intuitive and quite simple to set up, hence why there was a desire from the community for such a feature. You can read more about the active-rep feature along with setup examples here.
Harnessing the power of your resources#
So what are the benefits of load balancing to your active-active master nodes? Numbers are what you might expect when using the resources of both machines. See below a benchmark test load balancing through HAproxy. More details on the setup for benchmarking results are in the footer.
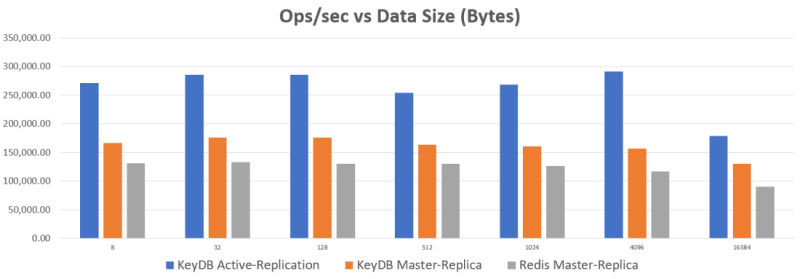
From the above chart it is clear that running with active replication has major benefits if you are not yet harnessing the power your replica node. For those who are already balancing the reads to the replica instance (client side) for KeyDB, you may not notice a big difference in performance between the two setups. With Redis, if you have already balanced reads to replica instances and are clustering you may not notice a big difference, but if you are running your server and not using the available computing power, KeyDB’s multi-threading can give you a big boost.
The above test used m5.large ec2 instances (2-core) and the servers were maxed out for the benchmark. KeyDB outperforms Redis here because it peaked out both cores (Redis not multithreaded). On a larger machine you can more than double the Redis perf of a single instance.
Conclusion#
Regardless of what database you are using, the important question to ask is if you are set up to fully utilize your resources. With open source KeyDB the idea is that you get a simple, open source setup option that enables high availability while fully utilizing your resources. If you are running Redis, you can achieve such a setup running sentinel nodes and clustering/sharding. If you have Redis Enterprise there is an active-active offering by Redislabs.
Check out this project on Github!
To learn more about active-replication click below:
- About Active Replication – read to learn more about active-rep, video tutorial, how KeyDB handles split-brain scenario
- Active Replication on Docker
- HAproxy Configuration with comments for KeyDB/Redis setup
Benchmarking#
For active-rep we balanced the benchmark read/writes round robin to both active-rep nodes (replicas of eachother). For the master-replica setups we run the same two nodes but in master-replica setup where traffic goes to master and the replica syncs. The benchmarking test here was performed with a m5.large instance (2-core) for each database instance as these are meant to be the bottlenecks. Each KeyDB instance had 2 threads enabled. A m5.2xlarge (8-core) was used for the RedisLabs Memtier client (benchmarking tool). Memtier was run with options: --threads=7 –requests=30000. This to ensure client was not the bottleneck and enough requests for consistent results. HAproxy was configured with 7 threads enabled to ensure it was not the bottleneck, tcp mode, and health check (see here for sample config file). HAproxy was run on a m5.2xlarge (8-core).