Implementing subkey expires for KeyDB
A long requested feature that Redis does not implement is the ability to expire individual members of data types with submembers such as SET and HASH. Redis' rationale for not adding this feature makes sense for Redis, but KeyDB is focused on delivering a high performance product that is easy to use and trying to implement this functionality without a built in command is hard, so adding this feature just made sense.
KeyDB's initial attempt at adding subkey expires was a straightforward one, for each expire add a vector for potential subkey expires, however this lead to certain performance issues. In this blog post we look at the root cause of those issues and how we used more complex data structures, such as hashtables, to solve them.
The EXPIREMEMBER command#
KeyDB implements subkey expires with a new command, EXPIREMEMBER. This command takes in a key along with a subkey and an expire time, and removes just the subkey from the data structure mapped to the key at the specifiied time leaving the rest of the value intact.
Here is an example with a HASH:
In the above example we set the member, f3, to expire in 10 seconds. 10 seconds later it is gone and the other members remain.
How KeyDB implements EXPIREMEMBER#
KeyDB expires keys and subkeys in two different ways, passive expires and active expires. Passive expires occur whenever a key or subkey is accessed and simply checks if that key or subkey is expired and removes it. Active expires are caused by an algorithm that KeyDB runs regularly during execution, KeyDB goes through pending expires and if any are due, removes the key or subkey in question.
An important consideration when implementing EXPIREMEMBER is how to store the expiry data for keys and subkeys, it should be stored in such a way that the active expire algorithm can quickly go through the keys and subkeys most likely to have already expired but also in a way that allows passive expires to quickly find the relevant key and subkey, all while minimizing the impact to KeyDB's memory usage. KeyDB uses a vector sorted by expire time, however this leads to a linear increase in lookup time during passive expire lookups resulting in a massive impact to other operations on values with pending subkey expires. In order to resolve this we consider using a hashtable which provides a constant time lookup instead.
Benefits of sorted vector:
- With a sorted vector the active expire algorithm can easily iterate through the pending expires and expire all the keys and subkeys that are due which enables KeyDB to ensure expired keys that are not frequently accessed are quickly removed.
- A vector is a memory efficient data structure using the least amount of memory needed to store the expires.
Drawbacks of sorted vector:
- Adding new expires and modifying existing expires requires a O(log(n)) search to ensure that it is placed in the right place, this can cause expire commands to slow down as the number of pending expires grows.
- Passive expires require finding the expire information for a specific key, in a vector sorted by expire time this requires an O(n) search, this results in a massive slow down in all commands accessing a key with a large number of pending subkey expires.
Benefits of hashtable:
- Adding new expires and modifying existing expires can be done quickly in O(1) expected time.
- Passive expires require finding the expire information for a specific key, in a hashtable this can be done quickly in O(1) expected time.
Drawbacks of hashtable:
- A hashtable makes it harder for the active expire algorithm to iterate through the pending expires, increasing the time to remove expired keys that are not frequently accessed.
- A hashtable is not very memory efficient, typically reaching optimal performance with a load factor of about 2/3, which means 50% more memory usage than a vector to store an equivalent amount of data.
Here is a graph comparing operations/second on a HASH object with 1000000 entries and n pending subkey expires with both implementations:
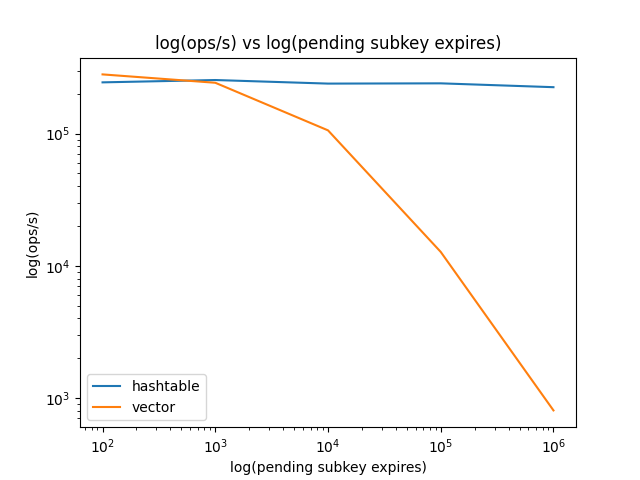
Based on these results switching to the hashtable seems to be the way to go!
Specializing the hashtable for EXPIREMEMBER#
The main drawback to switching to a hashtable is the impact on the active expire algorithm's ability to iterate over the pending expires in a way that allows it to find overdue expires first. Some modifications we made include:
- Sorting individual buckets within the hashtable by expire time, each bucket has a fixed constant maximum amount of entries so keeping them sorted has an O(1) cost.
- Creating a smart iterator that visits buckets in order, in combination with 1. this minimizes the amount of undue expires we look at when iterating over the table.
Switching to the hashtable gives us clear performance improvements to the passive expires, and by minimizing the impact to the active expire algorithm by using a modified hashtable that improves the probability of quickly finding expired subkeys we end up with an upgraded implementation that improves KeyDB's ability to offer the EXPIREMEMBER command without impacting overall performance.
Try out KeyDB#
If you like these features, want to try it out, or want to learn more, you can find the open source project here, or you can check out our docker image.
Keep up to date with KeyDB#
We have some really cool features in the works. To keep up to date with what we are doing follow us on one of the following channels: