Diagnosing performance issues on a superfast database ⚡
Have you ever worried about how your database will react when you get that major traffic spike? Or whether you can sustain high performance for a growing number of daily active users? When you have software that's capable of reaching blazing speeds, every part of your setup needs to work in tandem to support them.
KeyDB is fast, which means we often run into these issues. It can be difficult to reach optimal performance due to various hardware bottlenecks, which is frustrating to users. Hardware issues can be tough to debug, though, and we need a way to diagnose these issues consistently. In our pursuit of a general solution to this problem, here's what we found.
Types of bottlenecks#
To oversimplify it, there are three reasons a database's performance might not be reaching nominal values.
- Not enough data is being sent to the server. This is the most common case, but also it's not an issue; it simply means you aren't saturating your system.
- The network cannot handle the volume of requests. This only applies if your server and client(s) are not on the same machine, but in that case, it is a common bottleneck. Networks can be quite slow compared to the volume your database is able to process, especially depending on its configuration.
- The computer hosting the server can't process the data fast enough. This is unlikely to be due to a true hardware limitation, especially considering that production database servers are usually hosted on fairly beefy machines. However, some KeyDB configuration options, if they aren't optimized to take advantage of the hardware it's being hosted on, can cause this.
So how do we determine which bottleneck we have? Well, we have access to information from both the client and server, which means we have all we need. We can simply send a high amount of load to the server, inspect our CPU usage on client and server to find bottlenecks there, and if we see neither, by process of elimination, the bottleneck is on the server.
The other piece of the puzzle is being certain we're sending enough load to hit a bottleneck in the first place. The answer is we slowly increase the load over a period of time while inspecting the rate of processed operations as we go. Once the amount of operations processed on the server per second stops increasing, we know we've hit a bottleneck - either because it's been maxed out, or it's not receiving all of the data we're attempting to send.
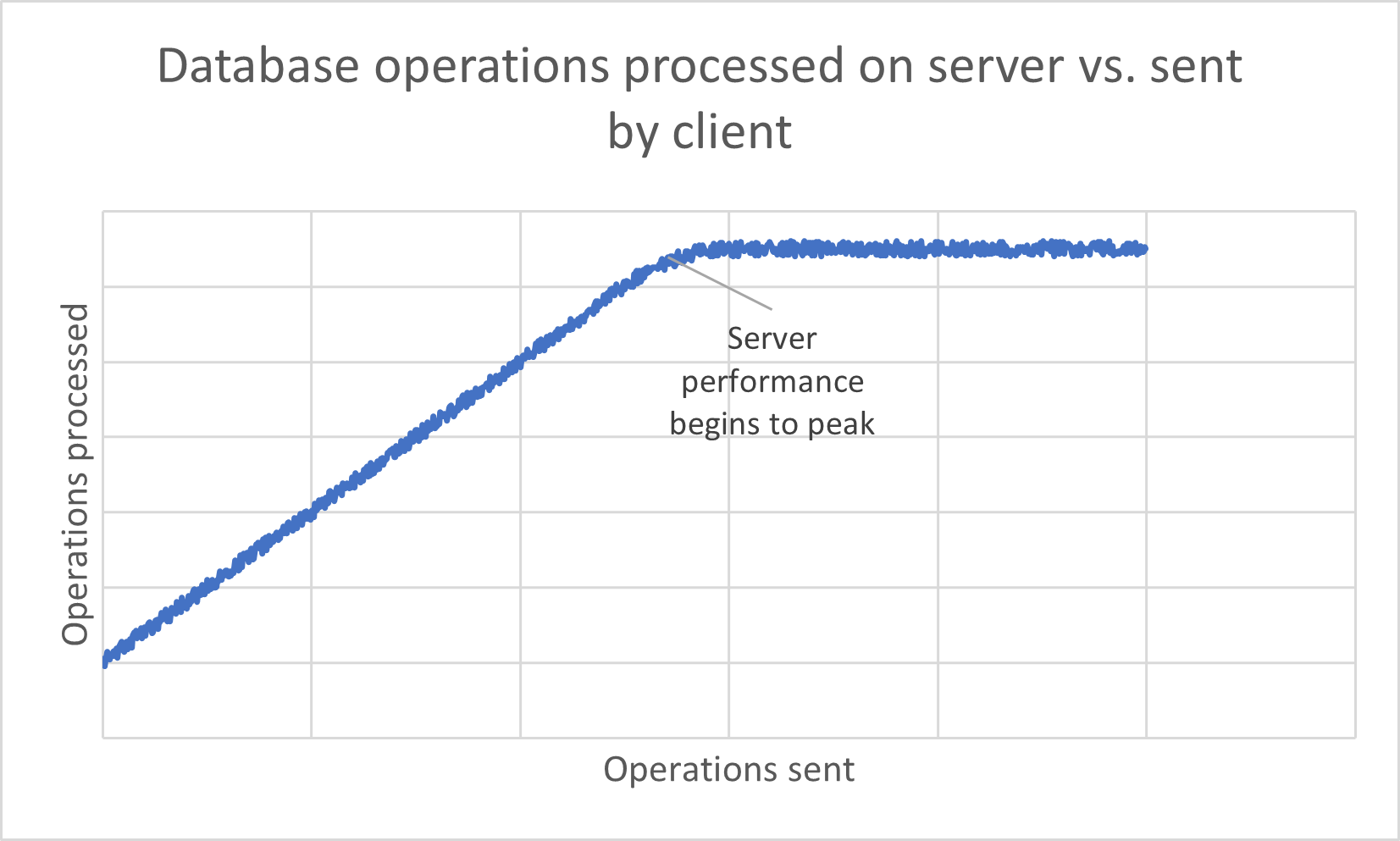
Diagnosing the causes#
Once we know where our bottleneck lies, what are the next steps? In order to be a useful diagnosis, we need to not only determine the bottleneck, but also probable causes and solutions.
If the client sending the load is the issue, there isn't much to do other than recommend testing with a different machine. It simply means the testing capabilities aren't currently enough to properly diagnose the server's issue.
The server's bottleneck is more interesting. While it's possible that the server's hardware just isn't powerful enough to keep up, that's a difficult problem to fix, and relatively unlikely considering the powerful hardware that database servers usually employ. Server configuration is a more likely culprit. In that case, there are some heuristics we can run to try and determine the cause. We can perform a config settings sweep: set the option to a value, run the bottleneck test, record the maximum performance, then change the option and repeat.
For example, much of KeyDB's performance is due to multithreading. If the server-threads option is set to an unoptimal value, performance will likely be impacted. By sweeping a range of possible values and charting the performance results, we can find the optimal setting. We can repeat this for other relevant configuration settings. Note that it is possible, in theory, for the performance of one option to be dependent on another. However, testing all the options together rather than one at a time increases complexity exponentially, and we expect this case to be rare enough that it's not something that would greatly affect the results.
Lastly, the network bottleneck. Once we determine that our bottleneck is on the network, there are a few things to consider. Firstly, networks commonly cannot handle the throughput to saturate KeyDB, such as Gigabit networks. There are some configuration issues to consider, however, including routers between the server and client, load balancing, and network queueing.
Automating the procedure#
As may have been obvious to the more technical-minded of you, such an algorithmic process lends itself well to being automated, and that's exactly what we plan to do. A tool for diagnosing performance issues saves a ton of time and effort, both on the part of the user and the developer. The last thing we at KeyDB want is for users to try out KeyDB only to not see the performance promised - especially when it's a solvable problem. Shipping a diagnostic tool along with the KeyDB binaries will allow users to independently solve their problems without requiring intervention from other parties, hopefully saving a lot of time and frustration.
We'll be building a tool with a focus on KeyDB as that's what we know best. The tool will spin up client threads while constantly checking server load and CPU usage and, as described above, wait until it stops increasing. Then we can determine where the bottleneck is and provide as much relevant information and as many probable solutions as we can.
The tool is currently in development, and we hope to release the first version in the coming weeks. We plan to continually add to the tool as we identify and diagnose more obscure issues over time.
Performance diagnosis takeaways#
The process of investigating this task has led to a few key points.
- Identify performance bottlenecks via load testing.
- Use heuristics built upon previous experience to diagnose the problem and provide solutions.
- Automate it all for maximum efficiency!
This simple procedure will allow us to help our users faster and provide better results. And while our focus was of course on KeyDB, there's no reason general idea can't apply to any database that's seeing performance issues. No matter how you use it, this paradigm will help your database be as powerful as it can be!
Keep up to date with KeyDB#
KeyDB is a supercharged drop-in alternative to Redis. We now have a community Slack workspace to discuss anything KeyDB! To keep up to date with what we are doing follow us on one of the following channels: