The effects of Redis SCAN on performance and how KeyDB improved it
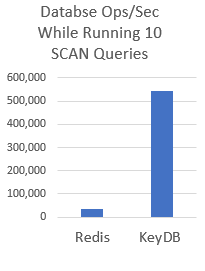
SCAN is a powerful tool for querying data, but its blocking nature can destroy performance when used heavily. KeyDB has changed the nature of this command allowing orders of magnitude performance improvement!
This article looks at the limitations of using the SCAN command and the effects it has on performance. It demonstrates the major performance degredation that occurs with Redis, and it also looks at how KeyDB solved this by implementing a MVCC architecture allowing SCAN to be non-blocking, avoiding any negative impacts to performance.
KEYS vs SCAN#
The SCAN function was created to break up the blocking KEYS command which could present major issues when used in production. Many Redis users know too well the consequences of this slowdown on their production workloads.
The KEYS command and SCAN command can search for all keys matching a certain pattern. The difference between the two is that SCAN iterates through the keyspace in batches with a cursor to prevent completely blocking the database for the length of the query.
Basic usage is as following:
The example below searches all keys containing the pattern “22” in it. The cursor starts at position 0 and searches through 100 keys at a time. The returned result will first return the next cursor number, and all the values in the batch that contained “22” in the key name.
For more information on using SCAN please see documentation here https://docs.keydb.dev/docs/commands/#scan
SCAN COUNT#
The COUNT is the number of keys to search through at a time per cursor iteration. As such the smaller the count, the more incremental iterations required for a given data set. Below is a chart showing the execution time to go through a dataset of 5 million keys using various COUNT settings.
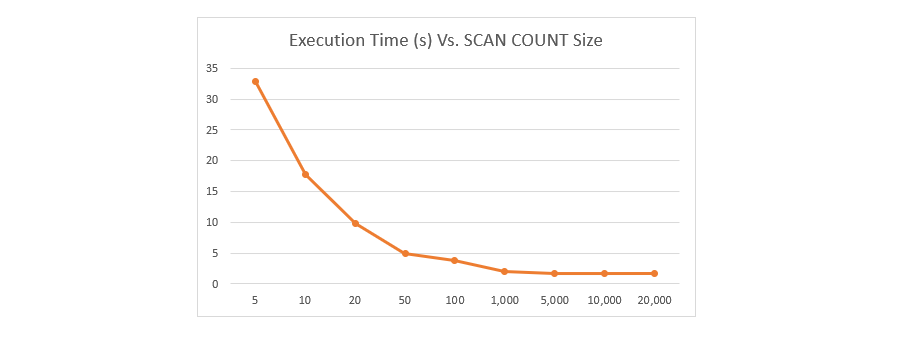
As can be noted, for very small count sizes, the time it takes to iterate through all the keys goes up significantly. Grouping into larger amounts results in lower latency for the SCAN to complete. Batch sizes of 1000 or greater return results much faster.
With Redis it is important to select a size small enough to minimize the blocking behavior of the command during production.
Redis Performance Degradation with SCAN#
With Redis, the KEYS command has been warned against being used in production as it can block the database while the query is being performed. SCAN was created to iterate through the keyspace in batches to minimize the effects.
However the question remains, how will SCAN impact production loads? If my COUNT size is small enough, can I run a lot of SCAN queries at once?
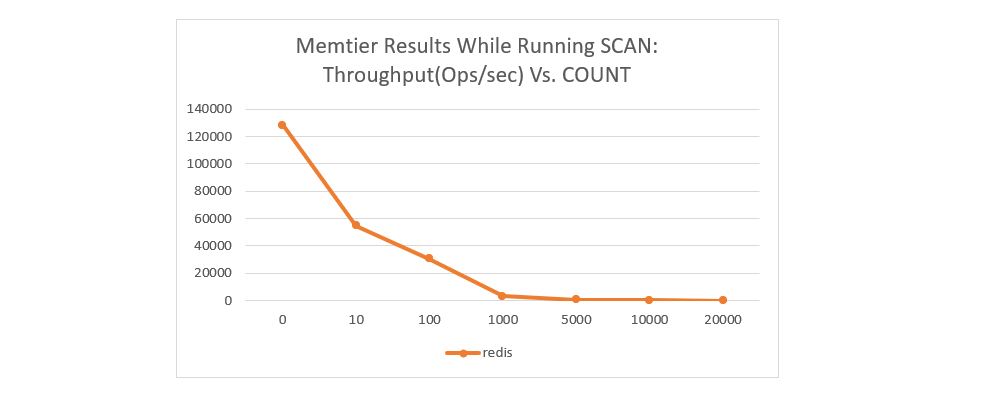
The chart below shows the effects of running SCAN on a large dataset with COUNT sizes of 100, 1000, and 10,000. It shows the effects that running the queries has on the existing workload’s performance.
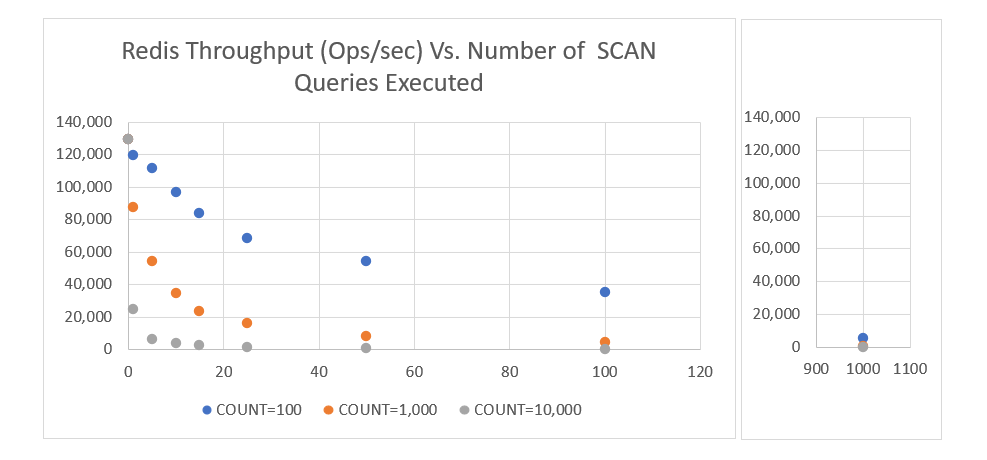
For the above, memtier was used to generate a workload, and a specific numbers of SCAN queries was run to see the effects on the workload.
The baseline ops/sec without running SCAN was ~128,000 ops/sec. It is obvious that as more SCAN queries are performed, the workload throughput becomes greatly reduced. The cumulative blocking effect of the many iterations becomes apparent fast. This means it is important to reduce the number of SCAN queries being performed to prevent reducing performance drastically.
KeyDB MVCC implementation with SCAN#
KeyDB has implemented Multi Version Concurrency Control (MVCC) into it's codebase. This allows a snapshot to be queried without blocking other requests. As such the effects of running KEYS or SCAN on KeyDB have little to no effect on the existing workload being run.
KeyDB is also multithreaded which enables much higher performance in general.
As it can be seen below, regardless of the COUNT or number of SCAN queries being performed, the workload being run is essentially unaffected.
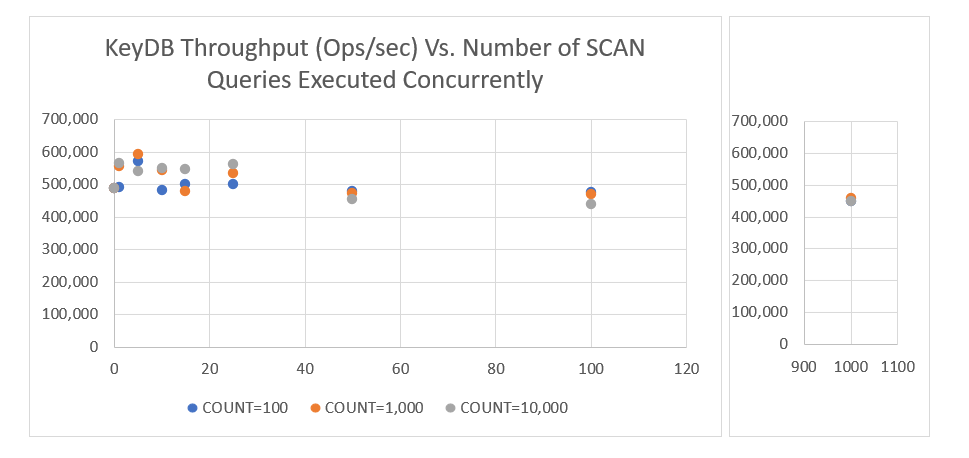
The performance does not degrade, and KeyDB is able to serve the SCAN queries concurrently. This can be great news for those who rely heavily on SCAN or need to apply it to their use case. The non-blocking behavior resulting from the use of MVCC as well as our multithreading provides a lot of opportunity we plan to build into KeyDB.
Python Example#
Below is an example of how SCAN might be used to iterate through the entire dataset. We use the KeyDB python library (Redis library also works), and define a function that accepts a pattern to match to, and a count size. The cursor starts at 0 and is updated each iteration and passed back until it reaches its starting point again (iterates through entire dataset).
Conclusion:#
Hopefully this article has provided some insight into how to use SCAN, it's impact on performance, and the improvements you can see with KeyDB's MVCC implementation.
We are very excited about the use of MVCC within KeyDB as it is opening a lot of opportunity to both improve performance, and to provide better insight into data. MVCC will in the coming year enable us to utilize more machine cores, and make huge leaps in what is possible with KeyDB.
Find out More:#
Test for Yourself#
For the tests above, we used the sample python code to query through the data. The dataset was 50 million keys in order to provide sufficient time to accurately measure the effects on throughput. The query would be requested in parallel up to 1000 times for the tests. The full dataset would be iterated through using different COUNTs.
While performing the queries a benchmark workload was generated using Memtier with its default settings: $ memtier_benchmark -p 6379. The recorded numbers were used to provide the data above. All tests were performed on the same machine (m5.8xlarge) running memtier and KeyDB/Redis on the same machine. It is possible to get higher throughput from KeyDB if Memtier is moved to its own machine, however for the purpose of this test, the setup was adequate to demonstrate the concept.
If you want to produce a similar load, you can have memtier run the SCAN command for you, however it will not iterate through the keyspace, only generate the requests for the one iteration. The effects seen however would be similar. Your database does not need to be very large to see the behavior below.
The command above produced the following effects on the standard memtier workload for Redis:
If using memtier for this you can limit the number of clients “--clients=x” to reduce the number of SCAN queries generated.