How Fast can A Single Instance of Redis be?
Redis is known as one of the fastest databases out there. But what if some of the limitations were removed, how fast could a stand-alone instance become? We often hear that Redis will likely become network bound or memory bound before it is CPU bound on performance limitations. Depending on your setup it could be any of these.
In this article we are going to discuss how we made a module that nearly doubles Redis performance!
Back to the question of being CPU bound or network bound, In our experience it is often both. EQ Alpha has put out KeyDB which is a multi-threaded, open source fork of Redis that proves multi-threading can make huge performance gains. However we were always bothered about another area that was a major bottleneck. Performance was often being held up in spinlocks and syscalls to the kernel. With big developments in NICs, Linux becomes a bottleneck on processing data packets. With kernel packet copy, interrupts and syscalls, the data being processed through the kernel is being restricted, this in the ‘kernel space’. On the other side we run our applications in whats called the ‘user space’. So the question becomes is there not a way to bypass the kernel? Yes, there is. Intel developed their Data Plane Development Kit (DPDK) which provides drivers and libraries to accelerate packet processing workloads . The idea of bypassing the kernel allows data streams to be processed in the user space while Linux deals with control flow.
This idea was put into practice and tested with the module just published by EQ Alpha. The module allows Redis to interact in user space with the NIC, bypassing the kernel. This allowed a normal Redis standalone instance to go from 164,000 ops/sec to over 300,000 ops/sec, with about a 1.8x latency reduction on a Redis 5.0 instance. The below chart shows Operations per Second vs Data Size. The tests were performed with the latest version of Redis (5.0), and with the Accelerator module added
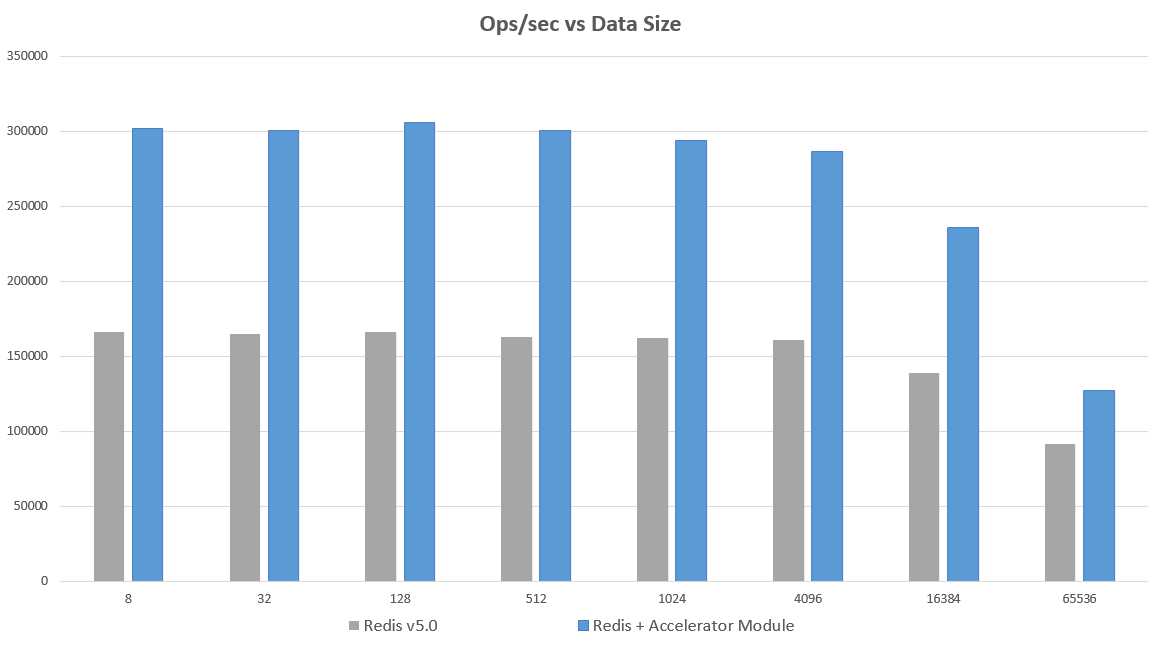
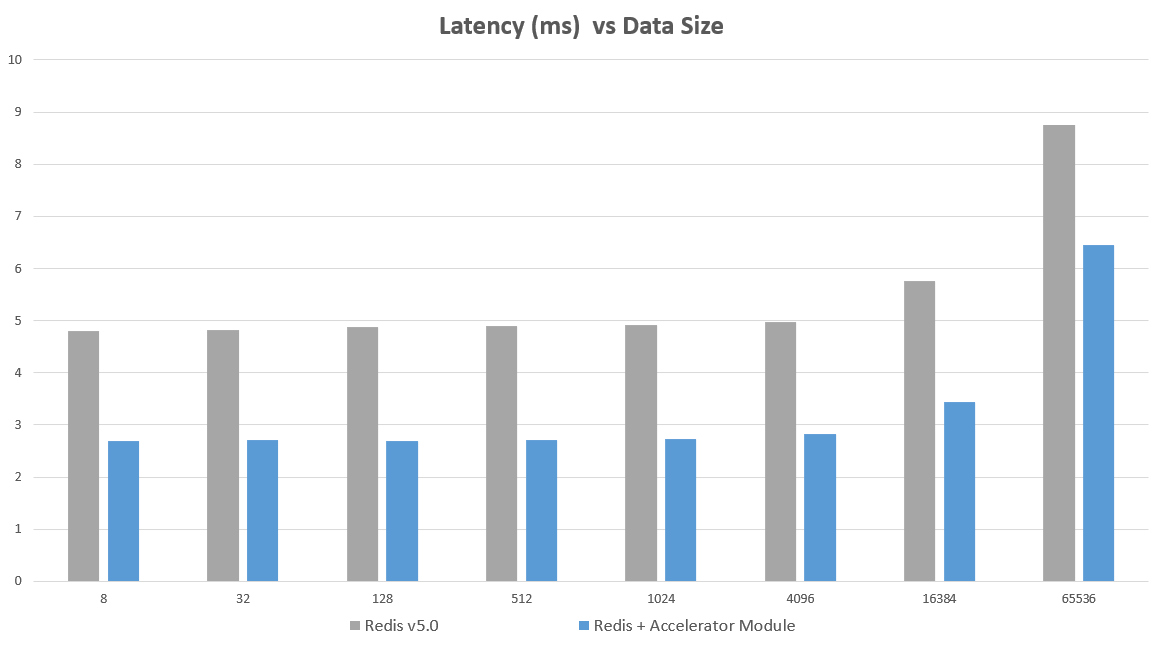
Benchmarks were performed with memtier-benchmark. Memtier was run on an m5.4xlarge machine and Redis was run on an m5.2xlarge. Memtier was run with 12 threads and 100 clients and tested to ensure this benchmark tool was not the bottleneck. Tests were performed on the same machines, with the same tests performed in each scenario. Pipelining was NOT used for these results. If pipelining was used QPS exceeds 2 million without major differences between methods. memtier_benchmark --clients=100 --threads=12 --requests=20000 -s <ipaddress> -a <password> --hide-histogram
The largest gains are seen on single machine instances (not running a cluster of nodes on the same server –although some gains can still be seen here). Running a master/replica on same server or as part of a machine cluster also has big gains. If the server is CPU bound, gains may not be as high. A machine with 4 or more cores is recommended
These are considerable gains, from operating within the userspace. Using this module allows your Redis instance to be used in this environment without modification to the base code. Redis will operate over Unix sockets which result in faster perf with dpdk. Using the Environment Abstraction Layer (EAL) along with other stack components, the module is able to poll and interpret the data without the overhead of interrupt processing. It is able to operate within its own framework and allows you to keep using your production version of Redis, or any other version of Redis on that note (including unstable and new releases).
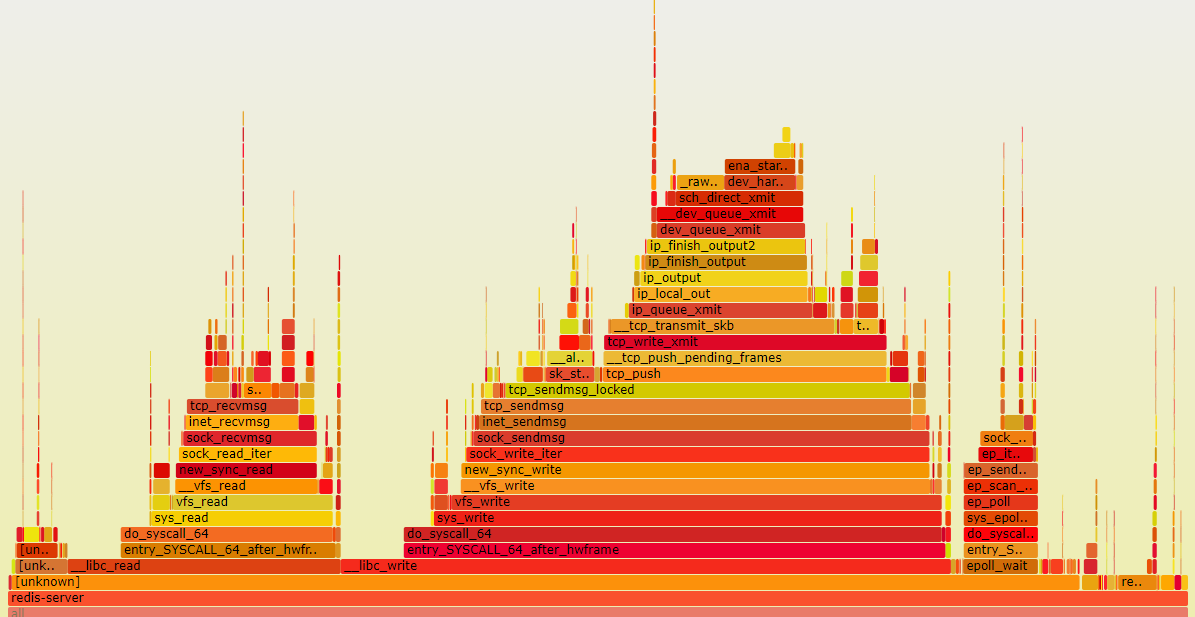
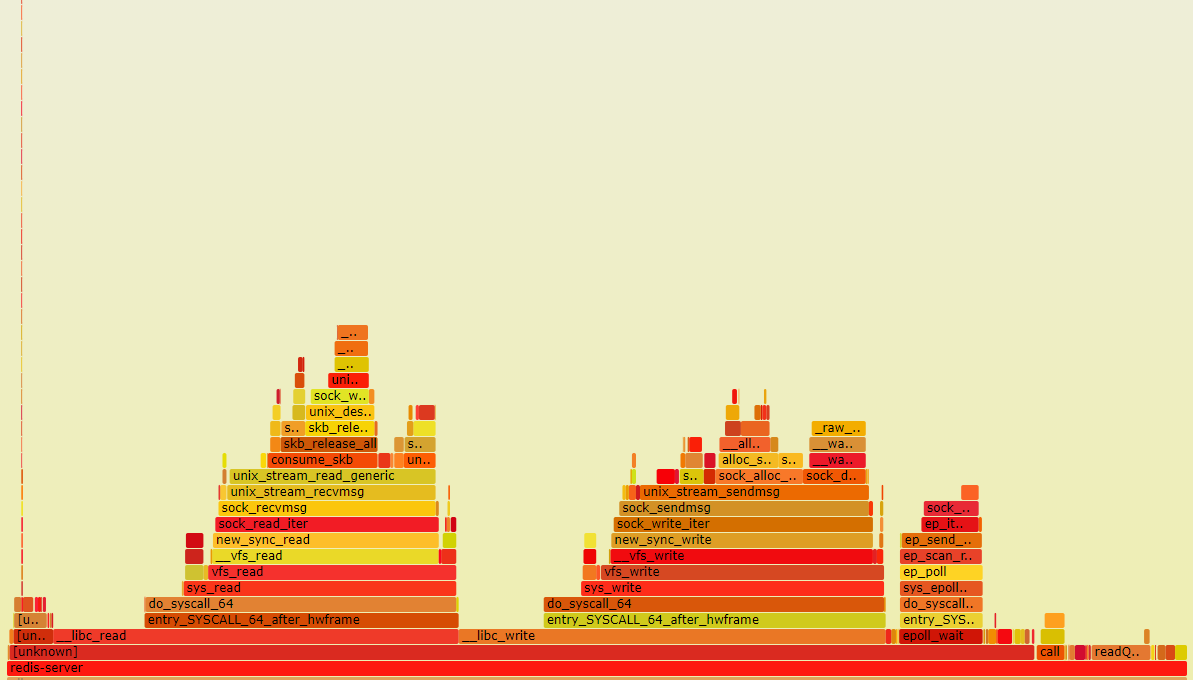
The concept is interesting and it jogs the curiosity as to whats going on inside. So what does it look like running a Redis instance without these limitaitons? Below are two Flamegraphs which can help provide a visualization of profiled software. They were generated while running Redis with the modules, and running it without:
Below is a flamegraph generated while performing a regular benchmark on unmodified Redis.
Below is a flame graph generated during the benchmark test with the Accelerator module running in the background:
Hopefully this article helps show the potential of what your instances can unlock. One of the goals of EQ Alpha with both this module and the KeyDB project is to help drive for options that enable larger more powerful instances that can minimize the need to shard and cluster by being able to handle more load. This module, being in a standalone module form, is beneficial because it will likely provide performance gains regardless of where the Redis base code goes next and with future versions.
For a translation in Russian please click here